多面体、鏡面
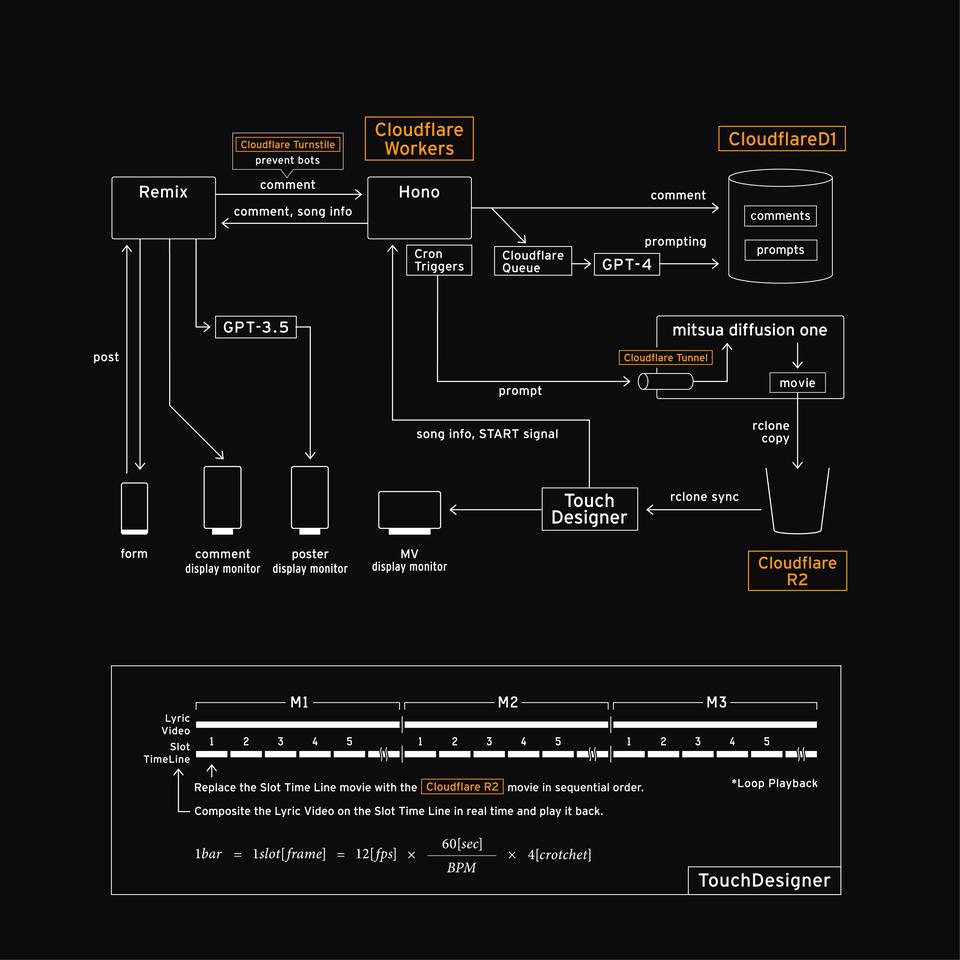
Polyhedron, Mirror surface同じ声データを反復する「音声合成ソフト」による歌唱。同じ再生を世界中で実現する「インターネットを通した音楽鑑賞」。一見すると「瞬間の芸術」とは対極に見えるが、果たして本当にそうなのだろうか。ユーザのコメントや反応と共に視聴される空間や、そこに彩られるれる何千万ものN次創作。人の数だけ存在するコンテンツの多様な選択と解釈の還元、再構成。これらのプロセスは複雑に絡み合い、全体としての表象や質を変化・拡張させていく。この時、一瞬一瞬の音楽体験には、どこかゆるやかにインタラクティブな一回性があるとは言えないだろうか。本作品は、こうした「再現や再生」の裏に隠れた、ユーザー毎の「選択や想像」の存在を捉え直し、一連のプロセスを空間上に再現することで、「CGM(消費者生成メディア)に眠る1回性」を検証する。まずはアーティスト「たなか」の声を、波形接続型の音声合成ソフトウェア「UTAU」によって合成音声化し、立ち絵とキャッチコピーを与え、新たな合成音声キャラクター「彼方(KANATA)」としてとしてパッケージする。彼方には異なるパターンの3楽曲を歌唱させ、それぞれMVと共に放映する。鑑賞者は、作品を見て思い浮かんだ単語や感想、色などの「想い」を、スマートフォンなどからフォームを通じて入力することができる。鑑賞者の入力はサーバーに回収され、内部で「生成システム」に受け渡される。すると、原初のキャッチコピーとMV映像に対し、システムがユーザーの「想い」を反映した新たな文や映像を生成、再構築し上書きする。生成システムは2系統から成り立つ。一つはMV生成系統であり、ここにはパブリックドメインやCC0、オプトインなど、権利的にクリアな形で収集された画像のみで学習された生成AIモデル「Mitsua Diffusion One」が組み込まれている。鑑賞者から回収された「想い」は、既存の著作物に依拠しない形に変換された上でAIモデルに供され、生成画像はリアルタイムでMVに挿入される。もう一つは文章生成系統であり、ここにはChat-GPTが組み込まれている。同じように、システムは「彼方」に与えられたキャッチコピーを「想い」を反映し上書きする。要素が置き換わった時、訪れた鑑賞者は自分より前の鑑賞者の「想い」が反映された作品を見ることになる。それを踏まえた想像がまた、新たな「想い」として回収され、作品に変化をもたらす。この「選択や想像」の循環が、ゆるやかに音楽や歌唱者の在り方を変化させ、その一瞬一瞬に「一回性の体験」を提供する。